ICTeNA TUTORIAL
ICTeNA est une interface (1) qui permet de naviguer dans les textes, ici ceux du journal "Le Petit Comtois" et d’y faire un certain nombre de recherches de façon extrêmement simple. Nous allons expliquer comment s’y prendre dans les lignes qui suivent.
- ICTeNA et la description des textes
- Pour l’instant explorons notre corpus, à l’aide de la première partie de l’interface
- La fonction « dictionnaire » d’ICTeNA
- La fonction « Recherche »
- Les fonctions « Co-textes » et « collocations
- La fonction "N-UPLETS"
Chaque article a été « décrit » grâce à ce qu’on appelle des « métadonnées »:
- une source (année de parution ; exemple : "1916")
- une date (exemple : "01/03/1916 ") ;
- des rubriques (exemple : "Chambre des députés");
- des signatures (exemple : "Sylvin");
- un titre ;
C’est aussi grâce à ces métadonnées qu’on pourra lancer une partie des recherches possibles sur l’important volume de textes rassemblés ici, et désormais ordonnés de telle sorte qu’on peut atteindre chaque partie du texte (mot ou partie de texte quelle qu’elle soit) pratiquement d’un clic de souris.
DEMARRAGE
Dans le répectoire dézippé précédemment à l'étape "Installation", nous aurons les fichiers suivants :

Un double clic sur l'icône "ictena.jar" ouvre l'interface suivante :
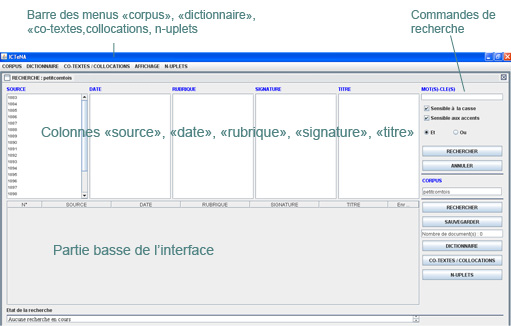
On repèrera des colonnes de gauche à droite nommées :
- " Source " [cet élément reprend chaque année de parution].
- " Date " qui correspond à la date d'édition.
- "Rubrique" et "signature"
- le titre de chaque article, lorsqu’il y en a un.
On voit enfin complètement à droite de l’écran un panneau avec des commandes qui permettront de lancer des recherches :
- « MOT(S)-CLE(S) » ;
- le nom informatique donné au corpus actif (en l’occurrence « petitcomtois ») ;
- si, plus tard on veut faire des recherches sur un mot ou sur un complexe de mots, on pourra choisir de cocher ou de décocher les opérateurs « et » et « ou » et les indications « [recherche] sensible à la casse », « sensible aux accents ».
Enfin on voit les deux commandes, l’une qui permet de lancer une recherche, l’autre de l’annuler.
Au-dessus de ces colonnes, on verra une barre horizontale : la barre des menus, dans laquelle figurent deux menus (en haut à gauche) :
- le menu « Corpus » (dans cette interface, on peut en effet facilement intégrer de nouveaux corpus de travail, à condition de procéder préalablement au nommage informatique dont nous avons parlé
(voir le site :http://adcost-elliadd.univ-fcomte.fr/ictena/) ;
- le menu « Dictionnaire », qui permet d’établir dans un premier temps, puis d’afficher ensuite la liste de toutes les unités de chaque texte ou partie de texte (tous les « mots », mais nous préférons dire « unités » ; nous reviendrons plus loin sur cette oscillation terminologique), et le nombre d’occurrences de chaque unité. Nous y reviendrons.
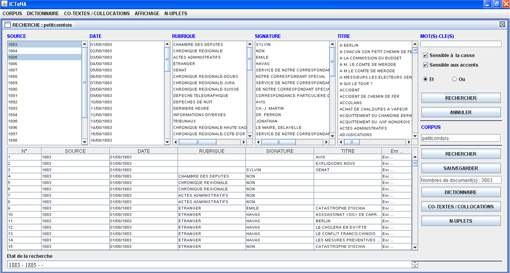
- On peut choisir d’explorer une seule année (1883, par exemple) : un clic sur "1883" met le texte en surbrillance ; puis clic sur le bouton « RECHERCHER » à droite.
- On peut choisir d’explorer plusieurs années (1883 et 1885) ou tous les textes répertoriés dans la colonne la plus à gauche (SOURCE) ; la souris met d’un clic les années choisies en surbrillance tandis que l’appui sur la touche ctrl de votre clavier permet de sélectionner plusieurs années ; puis clic sur le bouton situé en haut à droite de l’interface : « RECHERCHER ».
- On obtient alors ce type de vue, qui fait apparaître des indications dans les colonnes de la partie haute, et simultanément dans les colonnes de la partie basse.
REMARQUES :
- Chaque colonne de la partie haute est pourvue d’un « ascenseur » horizontal et vertical qui permet de visualiser correctement les contenus (pointeur de la souris sur l’ascenceur, clic gauche, maintenir enfoncé et mouvements de descente ou de montée).
- Chaque colonne du bas peut également être élargie, selon les besoins de la lecture, comme on le fait dans Excel, par exemple.
Cette première exploration, menée sur 1883, délivre les résultats suivants :
la liste des dates des articles traités, leurs rubriques, signatures et titres par ordre alphabétique. Le nombre « d’articles » est aussi affiché.
Dans la partie basse de la vue,
- chaque colonne permet une mise en ordre
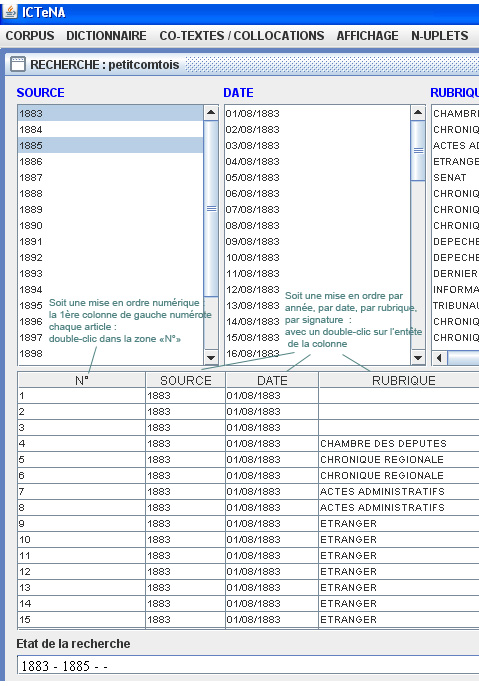
- On peut enfin accéder à la lecture de chaque article en cliquant dans la colonne gauche sur le texte numéroté qui nous intéresse. On obtient alors l’ouverture du texte dans une fenêtre comme ci-dessous :
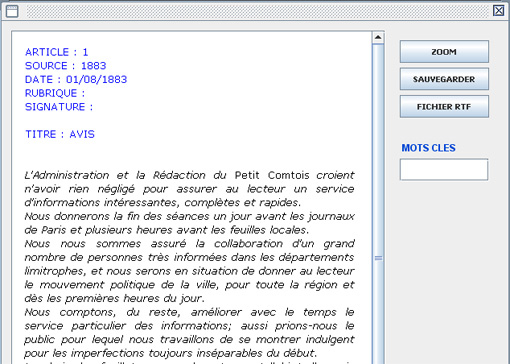
Remarque : on referme chaque fenêtre ouverte très classiquement : en cliquant en haut à droite dans le symbole : X
ICTeNA permet de recenser toutes les unités dun texte et de les compter. Cest le résultat de ces opérations automatiques quon appelle ici un « dictionnaire ».
Pour construire ce dictionnaire :
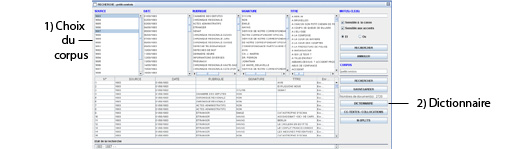
Retournons à l’interface initiale à l’aide du menu « corpus » puis des sous-menus « ouvrir > petitcomtois » situés en haut de l’écran.
- On sélectionne dans la partie haute de l'interface une série d'articles , par exemple 1883 : clic pour mise en surbrillance puis clic dans la partie haute sur le bouton « RECHERCHER».
- Dans la partie basse de cette interface, à droite, on clique sur le bouton « DICTIONNAIRE ».
Après quelques minutes, on obtient un tableau qui souvre dans une fenêtre comme dans la vue suivante :
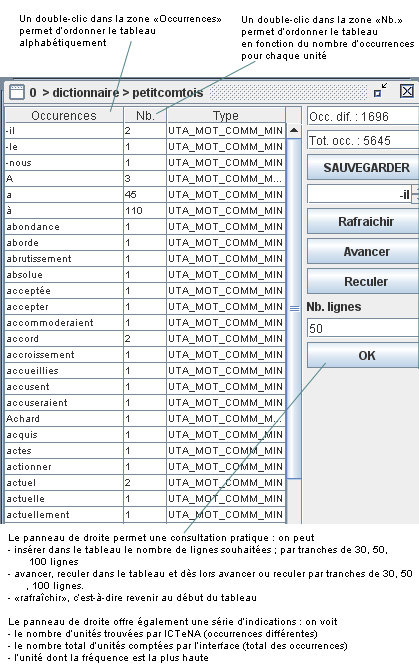
Recherches à partir du dictionnaire :
Retour aux textes où l'unité figure :
-
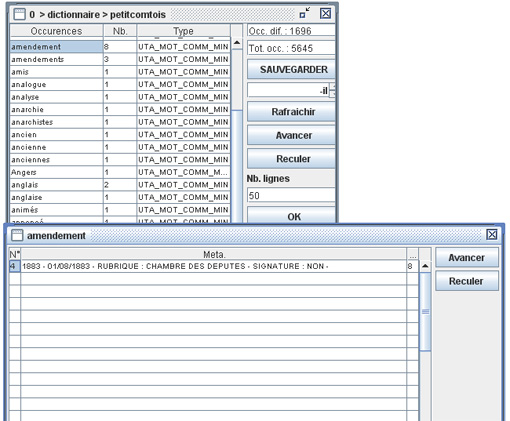
Si on clique sur l’une des occurrences du tableau, l’interface met à disposition la liste de toutes les parties du texte dans lequel elle est présente (cf. figure suivante).
-
Un clic dans la colonne « N° » de cette liste permet d’ouvrir chaque texte dans lequel l’unité figure. L’unité est alors surlignée automatiquement en rouge dans le texte.
-
Dans le panneau de droite, on trouvera pour chaque texte l’indication du nombre d’occurrences trouvées.
Recherche sur les contextes :
Fenêtre des contextes :
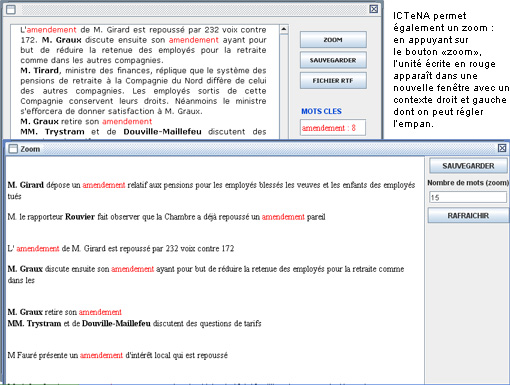
Sauvegarde et exportations des résultats jugés remarquables :
À chaque fois, on peut sauvegarder le texte ou les contextes obtenus dans des fichiers exportables (au format .txt), extérieurement à ICTeNA (Bouton « SAUVEGARDE » contenu dans le panneau de droite des dictionnaires ouverts).
REMARQUES IMPORTANTES
- On peut créer un dictionnaire, soit à partir d’un grand texte entier, soit sur une partie des articles, qu’on choisit dans la partie haute de l’interface.
- On peut créer et sauvegarder autant de dictionnaires que l’on veut, puis les appeler (à partir de la barre des menus du haut, menu « dictionnaire », où les dictionnaires sauvegardés apparaissent).
- Une fois les dictionnaires sauvegardés, on peut appeler et dès lors aligner et comparer jusqu’à 3 dictionnaires en même temps. Dans la figure suivante, deux dictionnaires sont ainsi alignés.
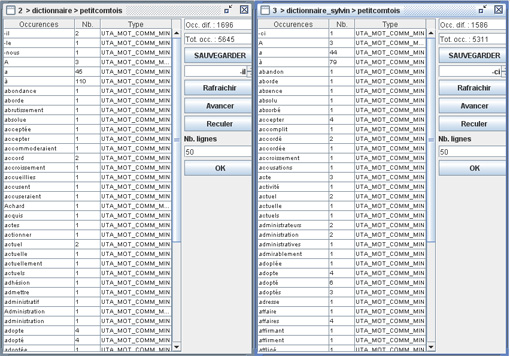
On a vu quon peut faire des recherches sur les unités et leurs contextes à partir des dictionnaires ; ces recherches portent donc sur une partie du corpus à chaque fois. Il est également possible deffectuer une recherche sans passer par létape « dictionnaire », et sur tout ou partie du corpus appelé.
Reprenons notre interface et
- mettons en surbrillance en haut à gauche « 1883».
- en haut à droite la case « MOT(S)-CLE(S) » : inscrivons par exemple « républicain », puis clic sur le bouton « RECHERCHER » en haut.
S’affichera alors en bas, le nombre d’articles dans lesquels on trouve au moins une occurrence de cette unité, et à nouveau les éléments seront hiérarchisables, les textes consultables, les contextes apparaîtront par la fonction ZOOM, etc.
La fonction recherche autorise les éléments suivants (panneau en haut à droite):
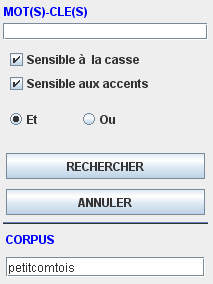
- recherche à propos d’une unité sur tout ou partie du corpus: inscrire l’unité
recherchée dans la case mot(s)-clef(s),
puis cliquer sur Rechercher
- recherche à propos d’une unité et d’une autre unité. Exemple : "anarchiste libre penseur" : cocher « ET »)
- recherche à propos d’une unité ou d’une autre unité.
Exemple : républicin acharné : cocher « OU »)
- recherche sensible ou non à la casse, sensible ou non aux accents.
- utilisation des jokers : le caractère : Ctrl + Alt + ¤ remplace n’importe quel caractère en début et(ou) en fin d’unité.
Nous pouvons affiner notre recherche : par exemple sélectionner les "dépêches de nuit-informations diverses" de l'année 1883 écrites par Sylvin. Il suffit de mettre en surlignance les métadonnées "1883", "Sylvin" et "Dépêches de nuit" puis de cliquer sur le bouton "RECHERCHER"
Il s’agit ici de déployer les premiers éléments d’une étude sémantique. Un mot peut changer, non de sens mais de valeur, selon le locuteur qui le prononce, et plus nettement encore selon le co-texte de son emploi, et selon les autres mots avec lesquels il voisine dans un énoncé. Il est donc important de pouvoir saisir une liste de mots, qu’on considère comme importants, comme conceptuels, ou comme caractéristiques du corpus, etc., (on les appellera ici des mots pivots) et de pouvoir visualiser et étudier l’ensemble de leurs co-textes.
La procédure est la suivante :
- On ouvre l’interface, et comme d’habitude maintenant, on choisit dans les SOURCES, le ou les articles qui sera ou seront étudié(s).
- On choisit éventuellement un ou des mots-clefs qui dès lors, délimiteront et sélectionneront les parties de textes à étudier.
-
Dans le panneau en bas à droite, on appuie sur le bouton « CO-TEXTES-COLLOCATIONS »
- Une fenêtre de dialogue s’ouvre, et vous demande de choisir si votre recherche sera
-
sensible ou insensible aux accents,
- sensible ou insensible à la casse,
- ou insensible à la casse mais sensible aux accents.
- Le formulaire vous demande ensuite si les mots sur lesquels porte votre recherche sont dans un fichier, ou si vous allez saisir cette liste de mots. Chacun entend bien que si la recherche est limitée à quelques mots, il sera plus simple d’entrer ces mots séparés par un espace dans la boite de dialogue, tandis que s’il s’agit d’une longue liste de mots, un travail préalable de constitution de la liste de mots dans un fichier (de type .txt, et constitué à partir du Bloc-Note de Windows, en saisissant un mot par ligne) est préférable.
- On suit donc les indications de la boite de dialogue et on lance la recherche.
- Attention, la constitution de ces données peut être très longue, notamment si les sources explorées par le moteur de recherche sont importantes.
- Une fois la recherche terminée, on aboutit à cette interface :
L’interface présente alors un tableau de ce type :
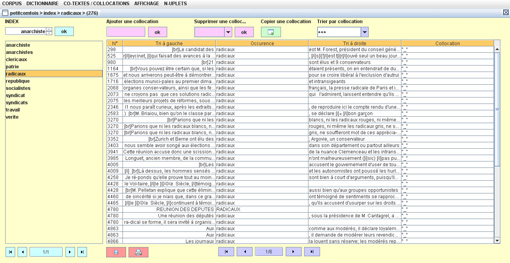
Comme à chaque fois, cliquer sur le N° à gauche dans le tableau permet d’ouvrir le texte où le mot figure :
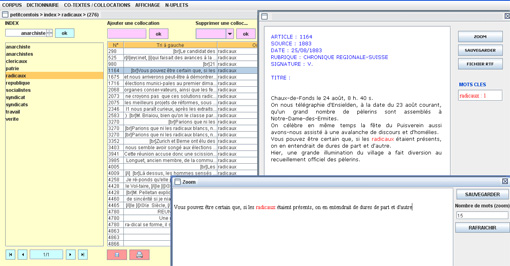
Le tableau est ensuite organisé de la manière suivante :
-
au centre le mot pivot
- à gauche et à droite son co-texte (comme dans Excel, par exemple, on donne à l’empan droite ou gauche la largeur qui convient pour pouvoir lire ce qui figure dans chaque colonne.
-
Un clic dans Tri à droite ou Tri à gauche permet de trier ces co-textes.
- La liste des mots- pivots peut être très longue. Pour s’y retrouver dans cette liste, on avancera ou on reculera grâce aux commandes bleu claires situées tout en bas de la colonne. ![]()
Plusieurs listes de mots pivots peuvent avoir été constituées. On les appellera l’une après l’autre à partir des commandes situées tout au-dessus à gauche.
Collocations
Enfin, on pourra réaliser une étude des collocations qui sont présentes dans le corpus : les mots entrent souvent dans des constructions plus ou moins figées ; on connaît l’unité « rez de chaussée » par exemple, ou « pomme de pin ». D’autres éléments entrent, dans tel ou tel texte, dans des constructions plus ou moins contraintes. Dans notre corpus de référence, on trouve par exemple : « républicain acharné », « anarchiste libre penseur », etc. Le travail suppose donc une phase d’examen de la liste des co-textes et de repérage des collocats. On entrera ces collocats dans la dernière colonne à gauche en utilisant les commandes roses « ajouter une collocation », « supprimer » ou « copier une collocation ».
Ce type d’études permet de vérifier que le mot-pivot est parfois très libre, c'est-à-dire sans collocation, ou avec peu de collocations remarquables, ou qu’il entre au contraire dans des constructions très figées, dont on pourra déployer la liste.
Comme toujours, on pourra sauvegarder une telle liste pour étude ultérieure ou même l’imprimer (cf. les icônes correspondantes en bas et en rose : ![]() ).
).
A noter : la liste des occurrences et de leurs co-textes peut être très longue. Pour s’y retrouver dans cette liste, on avancera ou on reculera grâce aux commandes gris clair situées tout en bas du tableau des occurrences.
Cette fonction cherche, là encore, à mettre en évidence les éléments figés dans un texte ou un discours (voir à cet égard les travaux d’A. Krieg-Planque, 2003 et 2006 sur la notion de formule). On suppose ici que les éléments figés peuvent se présenter comme des doublets (par exemple « classe stérile » au XIX° siècle, ou « devoir de mémoire », « fracture sociale » tout près de nous), des triplets (« j’ai fait un rêve », « une certaine idée de la France », etc. D’où le nom de N-Uplets attribué à cette fonction.
La différence avec la fonction précédente provient du fait que celle-ci autorise une extraction automatique, sans passer par la constitution préalable d’un index. On remarquera également que toute formule se présente à la fois comme figée mais aussi susceptible de variation (« fracture sociale » versus « fracture numérique ») ou de défigement (« devoir de se taire » ?). On ne cherche donc pas strictement et seulement des séquences graphiques identiques, mais on fait travailler un algorithme susceptible de coupler chaque unité du corpus avec toutes les unités suivantes sur un empan de 8 à 12 unités ou jusqu’à la fin de la phrase. C’est cet algorithme qui autorise d’extraire alors non seulement les séquences strictement identiques mais aussi des séquences qui supportent des variations.
Par ailleurs l'application permettra d'afficher non seulement des listes de n-uplets mais aussi leur co-texte et de retourner ensuite d’un clic aux articles dans lesquels ils figurent.
La procédure est la suivante :
- a) Remplir la boite de dialogue
- b) Construire un anti-dictionnaire
- On ouvre l’interface, et comme d’habitude maintenant, on choisit dans les SOURCES, le ou les articles qui sera ou seront étudié(s).
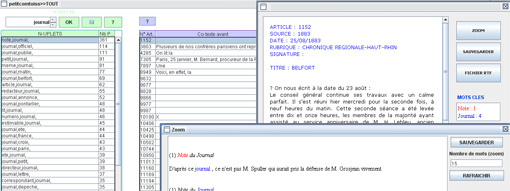
- En cliquant sur le bouton "N-UPLETS" nous obtiendrons le panneau des paramètres de recherche des n-uplets qui limiteront notre recherche. Chaque item proposé est expliqué en cliquant sur le bouton "?".
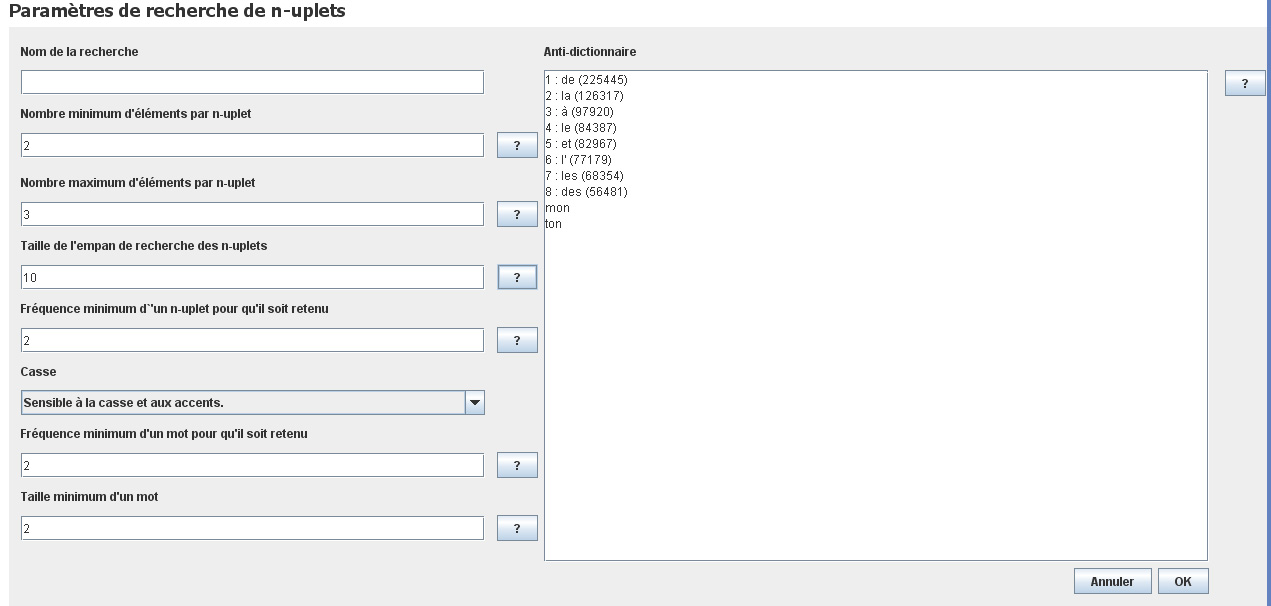
(Agrandir cette vue)
- Cette boite de dialogue est conçue pour que l’algorithme de recherche se plie aux besoins de chacun ou de chaque objectif de recherche, permettant d'obtenir une liste de n-uplets aussi pertinente que possible tout en diminuant les temps de calcul.
- Il faut commencer par donner un nom à la recherche.
- On voit ensuite qu’on peut demander à rechercher des séquences qui comprennent un nombre minimal et un nombre maximal d’éléments semblables.
- Il faut ensuite régler l’empan cotextuel. Par exemple 8, 10 ou 12 mots à droite et à gauche.
- On choisira la fréquence à partir de laquelle on estimera que les figements recherchés sont significatifs : 2 fois ou 3 ou 5 etc… Par défaut l’interface propose de ne conserver que les n-uplets présents au moins deux fois dans le corpus.
- Comme chaque fois, on choisira de lancer le calcul sur le corpus en le rendant sensible ou non à la casse et/ou sensible ou non aux accents.
- Les unités peu représentées dans le corpus sont exclues à l'aide du champ "Fréquence minimum d'une unité pour qu'elle soit retenue". Quoi qu’il en soit, pour chaque item proposé dans cette boite de dialogue on trouve une aide et une explication en cliquant sur le bouton d’aide noté : "?" correspondant.
- Un anti-dictionnaire est une liste d’unités exclues du champ de la recherche. Cette étape est indispensable pour plusieurs raisons : d’une part parce que ce type de recherche sollicite les capacités de calcul de l’ordinateur de façon très importante, et il faut donc le soulager autant que possible pour réduire les temps de calcul. D’autre part parce que les unités n’ont pas toutes le même statut : certaines unités correspondent à des mots-pleins, qui entreront effectivement dans des formules figées, mais d’autres correspondent à des mots-outils qui n’ont pas de pertinence pour le type de recherches engagées ici. Enfin, c’est en éliminant un certain nombre d’unités de la recherche, notamment les mots-outils, qu’on pourra obtenir certains figements comportant des éléments de variation. On verra alors ce type de liste se former et le nombre de phrases dans lesquelles ils se trouvent :
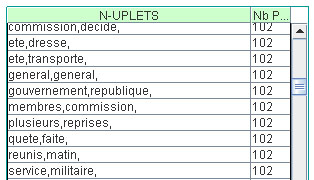
Mais auparavant, on doit poursuivre le travail de construction de l’anti-dictionnaire :
- Il est recommandé de retirer les unités ayant un tout petit nombre de caractères : 2 ou parfois 3 caractères. Ce 1° paramètre est saisi dans le champ "Taille minimum d'une unité mot ".
- D’autre part, à l'ouverture de l'interface de 'Saisie des paramètres', Ictena propose les 200 mots les plus présents sur tout le corpus en les affichant dans le champ "Anti-dictionnaire". On modifiera cette liste :
- en supprimant une unité (toute la ligne doit être supprimée)
- en ajoutant si on le souhaite chaque nouvelle unité sur une nouvelle ligne.
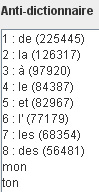
Finalement, nous lancerons la recherche à partir du bouton "OK".
- Après une attente qui peut être très longue dans le cas de corpus important, nous aurons l'écran suivant.
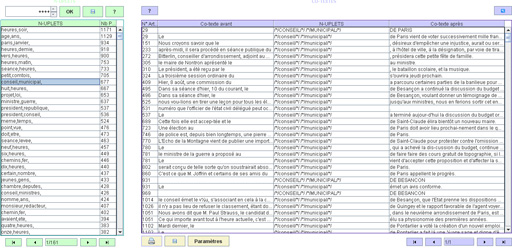
La liste des n-uplets ainsi que le nombre de phrases dans lesquels ils sont présents s'affiche à gauche. Un clic sur un n-uplets affiche les co-textes sur le volet droit. On navigue dans ces tableaux à l'aide des flèches situées en bas et les boutons "?" indiquent à chaque fois les options proposées sur chaque tableau.
Si nous décidons par exemple de ne sélectionner que les n-uplets contenant le mot "journal", nous afficherons ce substantif dans le menu déroulant en haut à gauche et cliquerons sur le bouton "OK".
Pour revenir à la liste complète , choisir le symbole "++++".
![]()
L'ordre d'affichage est modifiable en cliquant sur les entêtes des colonnes : par ordre alpabétique en choisissant 'N-uplets' et par ordre de fréquence dans les phrases en cliquant sur 'Nb. Ph...'.
De même, pour le tableau des co_textes, nous afficherons les "n-uplets" par ordre alphabétique en cliquant de même sur l'entête 'N-UPLETS' et reviendrons à l'ordre initial par numéro d'articles en choisissant l'entête 'N° Art.' .
Vous atteindrons le texte de l'article et le "zoom" en cliquant sur le numéro d'article comme dans les autres fonctionnalités d'Ictena.
ICTeNA permet l'enregistrement des résultats dans un fichier texte en cliquant sur les boutons ![]() : la liste de tous les n-uplets avec celui du haut et la liste des co-textes sélectionnés avec celui du bas.
: la liste de tous les n-uplets avec celui du haut et la liste des co-textes sélectionnés avec celui du bas.
__________________________________
(1)Cette interface est développée conjointement par Nicole Salzard (ingénieur en développement et déploiement d’applications) et Philippe Schepens (professeur des universités), au laboratoire ELLIADD - équipe ADCoST (Université de Franche-Comté), pour répondre à des besoins d’analyse de textes aidée par informatique.
Interface de Consultation de Textes Numériques en vue de l'Analyse
(Dernière mise à jour : juin 2016)